
I recently had some discussions with some coworkers and fellow graduate students and felt a bit lacking in my explanations regarding element inversion and the difference between interpolatory and non-interpolatory basis functions. I decided to make some visual examples inspired by the unpublished textbook by Prof. Carlos Felippa and thought I’d share some thoughts in this post.
First, it’s probably good to point out that while there are several approaches to defining a finite element, the approach most commonly used (and the one I’m going to write about) is the isoparametric finite element. Technically, you’ll find siblings of this approach called superparametric or subparametric, so let’s just call the general concept: parametric finite elements. What is meant by this approach is that we can define a mapping between a standardized element that lives in it’s own parametric coordinate system, and each of the instantiated elements (i.e. transformed elements) of a mesh that live in a unified, global coordinate system. What this enables is the one-time definition (e.g. quadrature) of a library of standardized elements, which can then be readily used for each of the (potentially) millions or billions of elements in the global mesh.

We then use some function that can transform information defined within the standard element into each of the elements in the global mesh. We call this “transformation function” a map, or mapping, or mapping function. So how about we demonstrate this by using a “real map” and let’s use 


In this next part, we’ll take a look at two different kinds of basis functions and explore this choice has in our mapping. But first, lets talk a bit more about the mapping function, specifically: what is the equation?

That’s not too much help as now we’re faced with new terms that we’ve not yet defined! First, lets just state what these things are, then later we’ll describe where these things come from: 
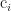
That’s all well and good, but how are you, the user, supposed to know where to put all these nodes? Well, we let the computer do that for us at various points, such as during mesh generation (see picture below) and during various stages of the finite element solve (e.g. residual convergence, contact constraints).

Notice that the elements interpolate the nodes.
Now let’s talk about the basis functions. There are two main classes of basis functions, interpolatory and non-interpolatory. The primary basis function family within the interpolatory class are the Lagrange Basis Polynomials. In the top image below are the basis functions for polynomial degrees: 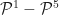
On the other hand, the Bernstein Basis Polynomials remain positive for all degrees and the magnitude of their oscillations diminishes with higher degrees. Now, it’s important to point out that any function that can be represented by a set of 

Lagrange Basis Functions, Degrees 1 to 5 
Bernstein Basis Functions, Degrees 1 to 5
The above basis functions are valid for a univariate element, but in the examples that we’ll eventually get to, we’ll construct bivariate basis functions by taking the tensor product of each set of univariate basis functions – leading to a standard element that is square:

Let’s talk a bit about interpolatory vs. non-interpolatory. If a function exactly passes through a set of points, we say that the function interpolates the points. If a function is constructed such that it accepts a set of points as input and then interpolates said points, it is an interpolatory function. Conversely, a non-interpolatory function accepts a set of points as input and returns an approximation of those input points. So it would seem that interpolatory functions are highly desirable, and in certain cases they are. But as we see in the figures below I’ve plotted some data that are representative of experimental measurements along with various fits, interpolatory and non-interpolatory, of the data.

P=9 interpolatory polynomial 
Piecewise P=1 interpolatory polynomials 
Spline approximation (non-interpolatory) 
Linear approximation (non-interpolatory)
Now, if I were to rank these various fits by almost any metric I would rank them, worst to best: Top-Left, Top-Right, Bottom-Left, Bottom-Right. A bit more explicitly and candidly:
- Top-Left
interpolatory polynomial
- Worse than nothing
- Top-Right
- Piecewise
interpolatory polynomials
- Better than nothing
- Piecewise
- Bottom-Left
- Spline approximation (non-interpolatory)
- Useful
- Bottom-Right
- Linear approximation (non-interpolatory)
- Really good
Hopefully this little exercise has removed the possible misconception that “interpolatory functions must be better than non-interpolatory.” So, now that we’ve defined how to compute the mapping, and at least introduced interpolatory and non-interpolatory functions, lets apply these ideas to our finite element mappings.
As you might imagine, it is valuable to not just talk about the value of mapped values, but also to talk about the derivative of the mapping. We call the derivative of the mapping with respect to the parametric coordinates, the Jacobian, and we write this as 

In two dimensions, this has the form:
![\mathbf{J} = \left[ \begin{array}{cc} \frac{\partial x}{\partial \xi} & \frac{\partial x}{\partial \eta} \\ \frac{\partial y}{\partial \xi} & \frac{\partial y}{\partial \eta} \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BJ%7D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+%5Cfrac%7B%5Cpartial+x%7D%7B%5Cpartial+%5Cxi%7D+%26+%5Cfrac%7B%5Cpartial+x%7D%7B%5Cpartial+%5Ceta%7D+%5C%5C+%5Cfrac%7B%5Cpartial+y%7D%7B%5Cpartial+%5Cxi%7D+%26+%5Cfrac%7B%5Cpartial+y%7D%7B%5Cpartial+%5Ceta%7D+%5Cend%7Barray%7D+%5Cright%5D+&bg=FFFFFF&fg=181818&s=4&c=20201002)
The Jacobian effectively describes the distortion of the mapping and we can use this to show how the orthonormal coordinate system of the standard element is changed for each point that undergoes the mapping.

We can then conveniently summarize this distortion as a scalar by taking the cross product of the transformed coordinate systems. Recall that in two-dimensions the magnitude of the cross product is the area of the parallelogram formed from the input vectors as shown in the below image. In three dimensions, this would be a parallelepiped and the measure would be its volume. Finally, if the sign of the cross product is negative, then the area (volume) is also negative and we would say that the finite element is inverted at this location — we’ve lost our bijective mapping.

An easy way to compute the cross product of these transformed coordinate system vectors, given the form of the Jacobian, is to take the matrix determinant:

Note that we often also call this value the Jacobian, so from here on I’ll refer to this value as the Jacobian, and the matrix found via 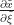


And notice what happens if we add in lines of constant 
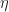

Can we invert this element? Yes, we can. In the animation below we pull the bottom-right node up to the top left node and we can watch as the element inverts — here the colormap goes from -1 to +1, centered around 0, so red means positive and blue means negative.

In this next section we will compare the interpolatory bases against the non-interpolatory bases to see how much we can move a single node (specifically, the bottom-right node) before the element inverts. But before we continue, try to think about what you would expect to see and maybe what the best you could hope for would be. Maybe sketch it out on paper. In each of the figure sets below, the interpolatory basis functions will be on the left, while the non-interpolatory will be on the right.
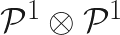











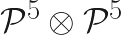


Hopefully you noticed a pattern for the behavior of both types of basis functions, and noticed the subtle differences between the two types. Admittedly, before this exercise I thought that for both basis functions the element wouldn’t invert until the bottom right node became colinear with the nodes immediately to its left and top, in a manner similar to the linear case. Instead we see that only the non-interpolatory basis functions have that property – for all degrees. And we note that for the interpolatory basis functions as we increase the polynomial degree the amount of allowable relative movement decreases.
In the video below we continue exploring the robustness to nodal deformation of the different types of basis functions. The video consists of sequences between interpolatory and non-interpolatory bases, for each sequence the exact same nodal deformation is prescribed.
One thing that stood out to me was that we can clearly see the Runge phenomenon emerging for the interpolatory basis functions. In one of the sequences, we find that we can actually invert the element by pulling a boundary node away from the element. This just feels wrong, it should give you a feeling of cognitive dissonance whereas the non-interpolatory basis appears to have a more sensible effect. Below is another example to help us compare the interpolatory vs non-interpolatory basis functions. Both examples have the same amount of nodal displacements, which were determined randomly between 0 and 0.05 (on a biunit domain). The same color scale is used for both and is centered at a value of unity — the closer to white, the better.

Perturbed biquartic Lagrange 
Perturbed biquartic Bernstein
You might be asking whether it’s valid to talk about such highly distorted elements, especially those with maybe one or two nodes that are excessively deformed. Wouldn’t the constitutive model spread the deformation across multiple nodes? Well, one area that this can show up, and during which there is no constitutive model to “spread out” the effect is in mesh generation. Below is an example of a part that contains a web feature that is filleted. Note that the linear mesh (left) has some highly distorted elements on the fillet boundary, but all elements are at least positive. However if we increase the element degree to 


Something I want to talk about now is, “but why do we care about the values of the Jacobian Matrix and the Jacobian?” We often use the (scaled) Jacobian as standard metric in determining our finite element mesh’s quality. But why? What’s the point? Let’s explore that question using that weird inversion example from the video. Let’d return to using a map-map, this time of 19th century Europe, to understand our map.

Now, imagine you’re a navigator on board a ship and, due to some most unfortunate events, the ink on your map runs, resulting in a “new” map that looks like the image below (minus the black lines) and you’ve also suffered a concussion whilst staving off a pirate attack, making you forget everything you knew about European geography — all the information you have is the ruined map. You can imagine that if you were traveling between England and Denmark, that you wouldn’t have too difficult a time reading the map and determining which direction you should travel. However, if you had to travel from Cyprus to Barcelona, it would be quite difficult. First of all, according to your map and due to the element inversion, Cyprus is both in the Black Sea and in the Mediterranean sea — it’s in two places at the same time! Luckily, as sheer dumb-luck would have it, a storm blows you to the west of Crete. Out of curiosity you try to read the names of a few landmasses that appear at the bottom of the map. Notice that while you would have had no problem reading Malta or Tunisia in the undamaged map, that instead on your damaged map the words are completely illegible. The high distortion of the map in this region has rendered it useless. This is analogous to the effect this has in our finite element code. The quality of the mapping directly impacts the ability of the solver to converge to accurate solutions.

Contrast the above exercise with the mapping below, where we used the same amount of nodal deformation. The map appears virtually unchanged in the northern regions and the southern regions, while deformed, are still legible and relatively easy to distinguish. Which map would you rather have?

Now, you might be saying “well that’s not fair, you should apply the same amount of distortion to both maps!” And well, we could. As both types of bases I presented are polynomial, they can exactly match any distortion that the other can produce. For instance, there is some arrangement of the nodes in the interpolatory case that would produce the better map that I showed, and vice versa there is some arrangement of the non-interpolatory basis’ nodes that would produce the horrifically disfigured map. But the point I’m making is this: In optimization problems we typically prefer to have a small relative change in the output for a given change in the input. We also prefer this change to have a monotonic effect on the output. Imagine a contact algorithm where we’re trying to optimize the placement of the finite element nodes to fulfill the contact conditions. Having a well behaved Jacobian is a key enabler to achieving robust convergence.

My penultimate comment hearkens all the way back to the beginning of this post. Not all elements are as dependent on this particular concept of the Jacobian. In fact, there are some formulations that allow for elements that we would normally consider inverted, but of course, they’re not inverted within the contexts of their use. A couple of these kinds of elements are those that use harmonic or barycentric basis functions. These methods don’t use this parametric map to build their basis functions in the global coordinate system, rather they explicitly build the basis functions within the global system. This means you can construct basis functions on elements like those shown below.




My final comment is that while we seem to commonly use the (scaled) Jacobian as a means of quantifying our mesh quality, this is usually shown to the user as a single value for the entire element (see image below) which I can only assume must be the Jacobian as calculated at the the quadrature point in a 1-point Gaussian scheme (

Hope you enjoyed reading this post. Let me know your thoughts and please point out any mistakes I’ve made!
